Σ|xk-x̄| = 285


If the data "sticks" were equal weight, the beam would balance at the mean.
The mean is the value that minimizes the sum of the squared residuals (the difference
between each datum and a number a) (aka squared deviations):
Σ(xi-a)2 is minimized when a=x̄.
Think of the squared deviations as a kind of "penalty," the mean is the point
where the total penalty (sum of squared errors) is as small as possible.
The mean is very sensitive to outliers because squaring
makes large deviations very costly.
The average distance from the mean is the MAD (mean absolute deviation) =
Σ|xi-x̄| / n
i.e. sum all the distances, divide by the number of them.
Unfortunately, the intuitive MAD plays almost no role in stats! The SD is used instead, for theoretical math reasons.
SD ≥ MAD.
In a normal distribution: SD=√(π/2) MAD ≈1.25MAD.
Uniform distro: SD=2/√3 MAD ≈1.155MAD.
Exponential distro: SD≈e·MAD
The median m minimizes the sum of absolute deviations: Σ|xi-m|.
The median is robust to outliers because it only cares about the distance,
not the square of the distance.
But the sum of the differences of the data values and the mean is zero.
Σ(xi-x̄) = 0
(Which is one reason why the standard deviation (SD) formula squares each difference.)
Σ|xj-x̄| = 285
Σ|xk-x̄| = 285

Σ|xj-x̄| ≈ 98
Σ|xk-x̄| ≈ 98

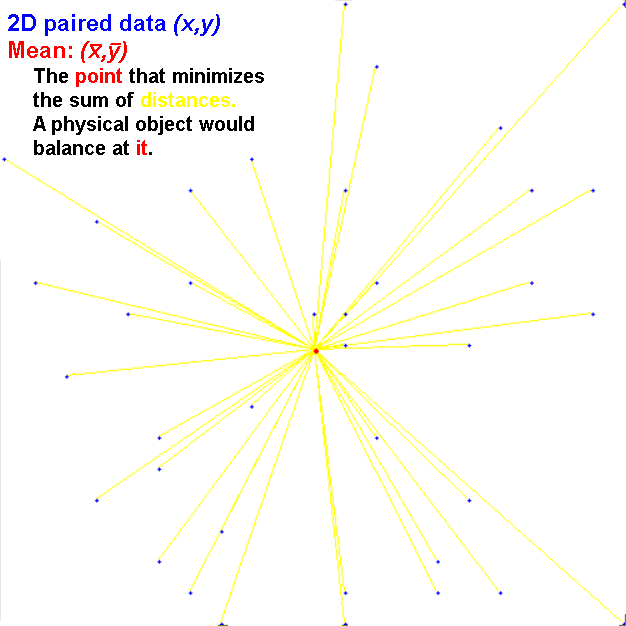
2D data:
The mean is a/the typical, representative member of normal, symmetric data set but not typical of bimodal data, nor of skewed data (the median is better).